如何建立独属于你自己的论文数据库
这一篇博文想和大家分享下如何利用zotero从0开始建立一套独属于你自己的论文数据库。
前言
日常生活中,我们会看很多论文、技术博客、书籍、分享。但是,很多东西我们看过就忘记了,或者说仅有模糊的印象,每次需要找的时候都需要找半天。而且长期的熬夜使我的记忆力衰退严重。我仔细研读了一些生物学知识, 记忆衰退大概率是一个不可逆的趋势。因此,我便想抓住另一个大趋势:文本资料的电子信息化。综上,我很想构建一个独属于自我的大脑数据库,也就是独属于自我的个人知识管理库。(也希望后面有闲暇的时候,继续填这个坑。)
有人会问,我们已经有Google这样的工具了,为何还要单独建立个人数据库呢?
一方面,我们逐渐进入到知识爆炸的年代,互联网上信息现在不是太少了,而是太多了。我们每天被大量的冗余、低效信息吸引、折磨。
另一方面,有时候我们需要搜索的领域足够的精准,最好能够匹配你个人的思维,而非通用型的搜索引擎。在信息初筛的时候,Google无疑是最好的工具;但在做一些精细化分析的时候,独特的数据库会更有用一些。比如论文的搜索,最好只搜索我关注的会议或者期刊,比如四大顶会或者清华网络安全推荐列表中的会议。这样整体可以节省我后续筛选论文的一些精力。
Zotero
Zotero是一个免费且开源的论文管理工具,支持跨平台、多种形式资料导入、各类插件等等.
Zotero支持几个有趣的功能:
- 基于bitex的文献批量导入
- 自动抓取论文pdf
其他具有上述功能的文献管理工具也能自动化构建。
DBLP
DBLP(DataBase systems and Logic Programming)是计算机领域内对研究的成果以作者为核心的一个计算机类英文文献的集成数据库系统。我们可以用它来搜索相关计算机领域的文献。
DBLP系统有这几个特点,比较有用:
- 网站组织形式清晰,非常容易爬取。
- 几乎没有反爬功能,不需要利用类似阿布云的IP代理池爬取,也不需要任意的动态浏览器爬虫来爬取。
- 收录相关会议的所有论文bibtex格式。
利用zotero与DBLP批量收集论文
首先,我们通过dblp网站爬取对应会议的录用论文bibtex.
代码如下:
(PS: 2020.10.30:修复原始代码的一个正则匹配bug.)
import requests
import re
import os
session = requests.Session()
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Cache-Control": "max-age=0", "Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:80.0) Gecko/20100101 Firefox/80.0",
"Referer": "https://dblp.org/search?q=NDSS", "Connection": "close",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate"}
cookies = {"dblp-search-mode": "c", "dblp-dismiss-new-feature-2019-08-19": "3"}
lib = {
"NDSS": "ndss",
"CCS": "ccs",
"S&P": "sp",
"Usenix_Security": "uss",
"DSN": "dsn",
"Raid": "raid",
"IMC": "imc"
}
def get_all_bibtex(url):
bibtexs = []
res = session.get(url, headers=headers, cookies=cookies)
data = res.content
assert res.status_code == 200
bibtex_urls = re.compile(r'https://dblp\.org/rec/conf/[a-zA-Z0-9]{1,10}/[a-zA-Z0-9]{1,30}\.html\?view=bibtex').findall(data)
# print(bibtex_urls)
# print(len(bibtex_urls))
bibtex_urls = list(set(bibtex_urls))
for l in bibtex_urls:
bibtex = get_one_bibtex(l)
bibtexs.append(bibtex)
print("[+] get one succ! {}".format(len(bibtexs)))
bibtexs = list(set(bibtexs))
return bibtexs
def get_one_bibtex(url):
res = session.get(url, headers=headers, cookies=cookies)
data = res.content
assert res.status_code == 200
try:
bibtex = re.compile(r'@[in]*proceedings{.*}', re.S).findall(data)[0]
# print(bibtex)
return bibtex
except Exception as e:
print(e)
print(data)
return '{}:error!'.format(url)
def check_exist(output):
file_path = 'bibtex/{}'.format(output)
if os.path.exists(file_path):
return True
return False
def main():
# year = 2020
# key = 'NDSS'
# name = lib[key]
year_start = 2015
year_end = 2016
for year in range(year_start, year_end):
for key in lib:
name = lib[key]
output = "{key}_{year}.bibtex".format(key=key, year=year)
if check_exist(output):
print("[-] {} {} bibtex exists! Continue...".format(key, year))
# continue
print("[+] Try to get {} {} !".format(key, year))
url = "https://dblp.org/db/conf/{name}/{name}{year}.html".format(name=name, year=year)
results = get_all_bibtex(url)
tmp = '\n'.join(results)
print("[+] Get all bibtex: {} {} Succ!".format(key, year))
with open('bibtex/{}'.format(output), 'w') as f:
f.write(tmp)
if __name__ == '__main__':
main()
爬取其他会议,请自行定式化lib,年份定制化year即可。
爬取完效果如下:
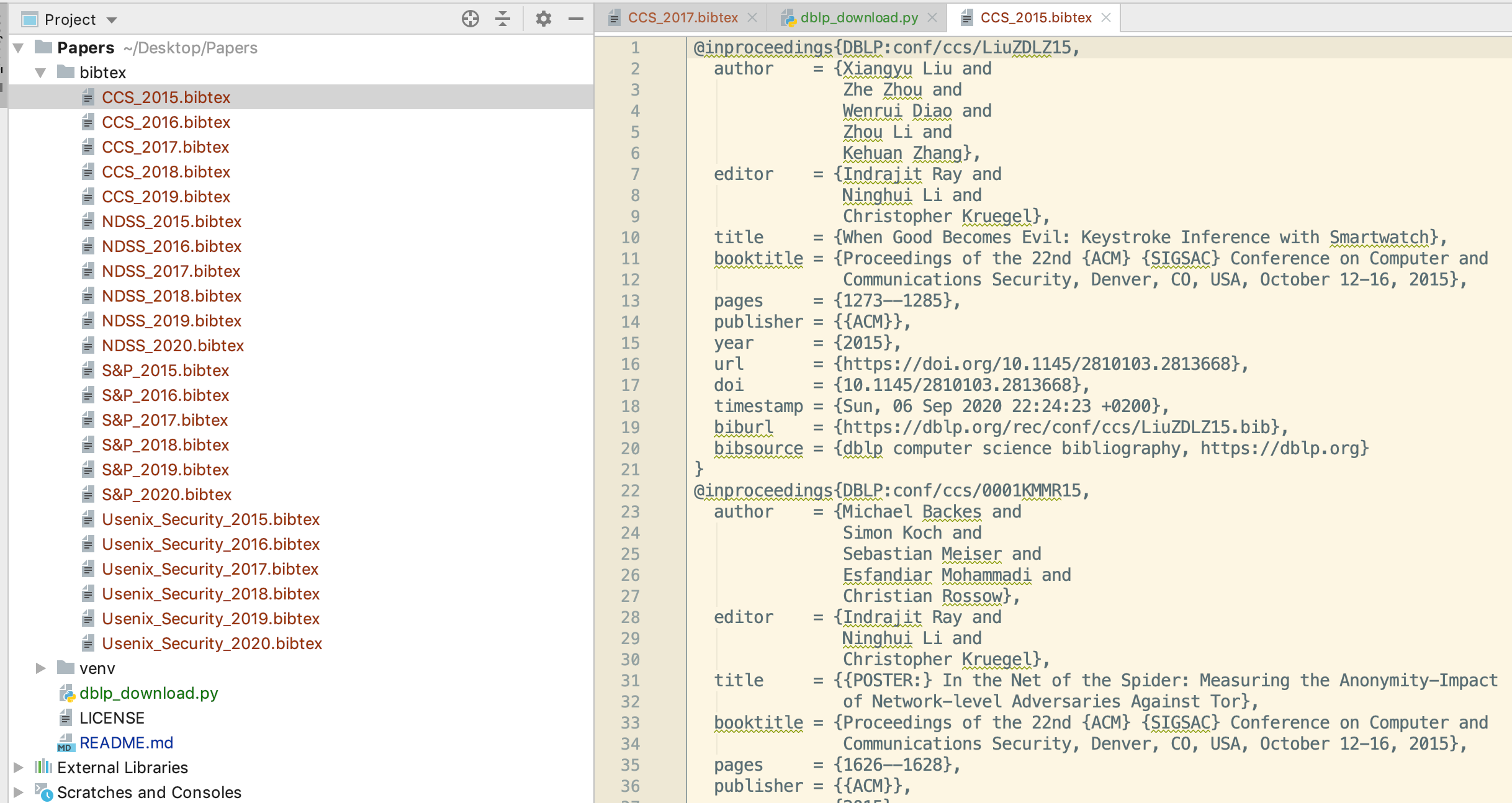
此时,我们使用Zotero的File->Import功能导入即可。
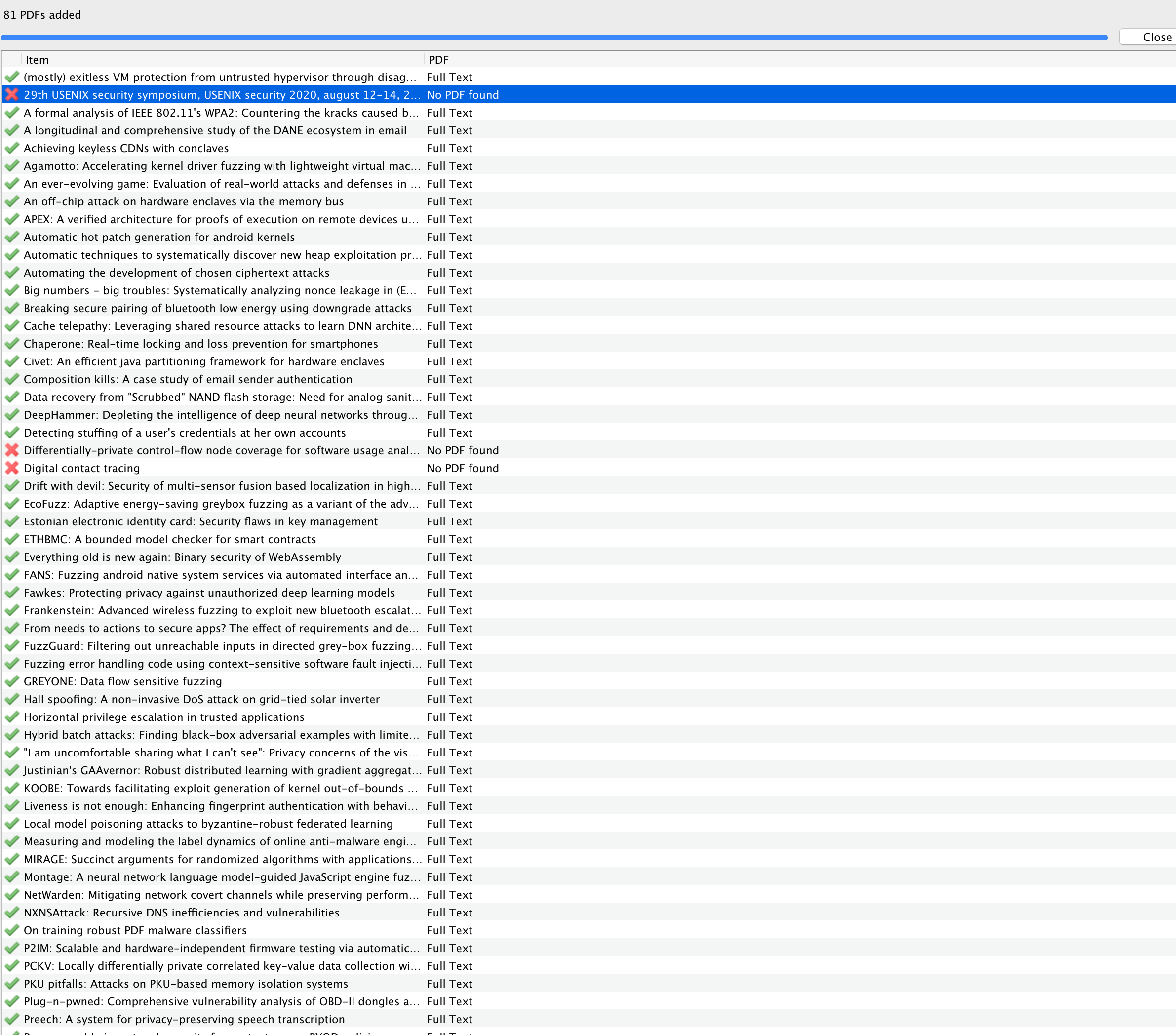
导入后,全选论文,进行抓取:
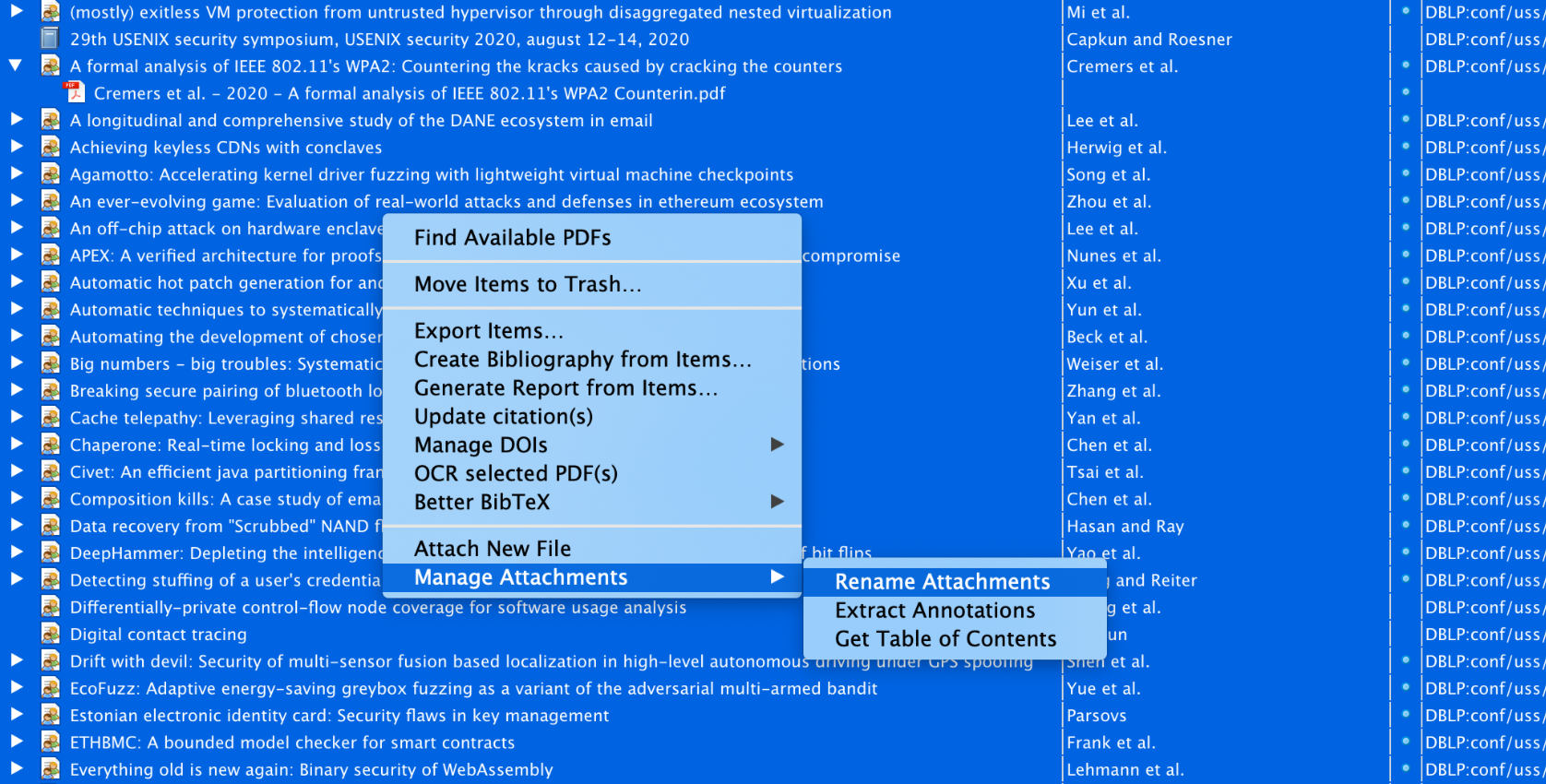
利用插件批量重命名:
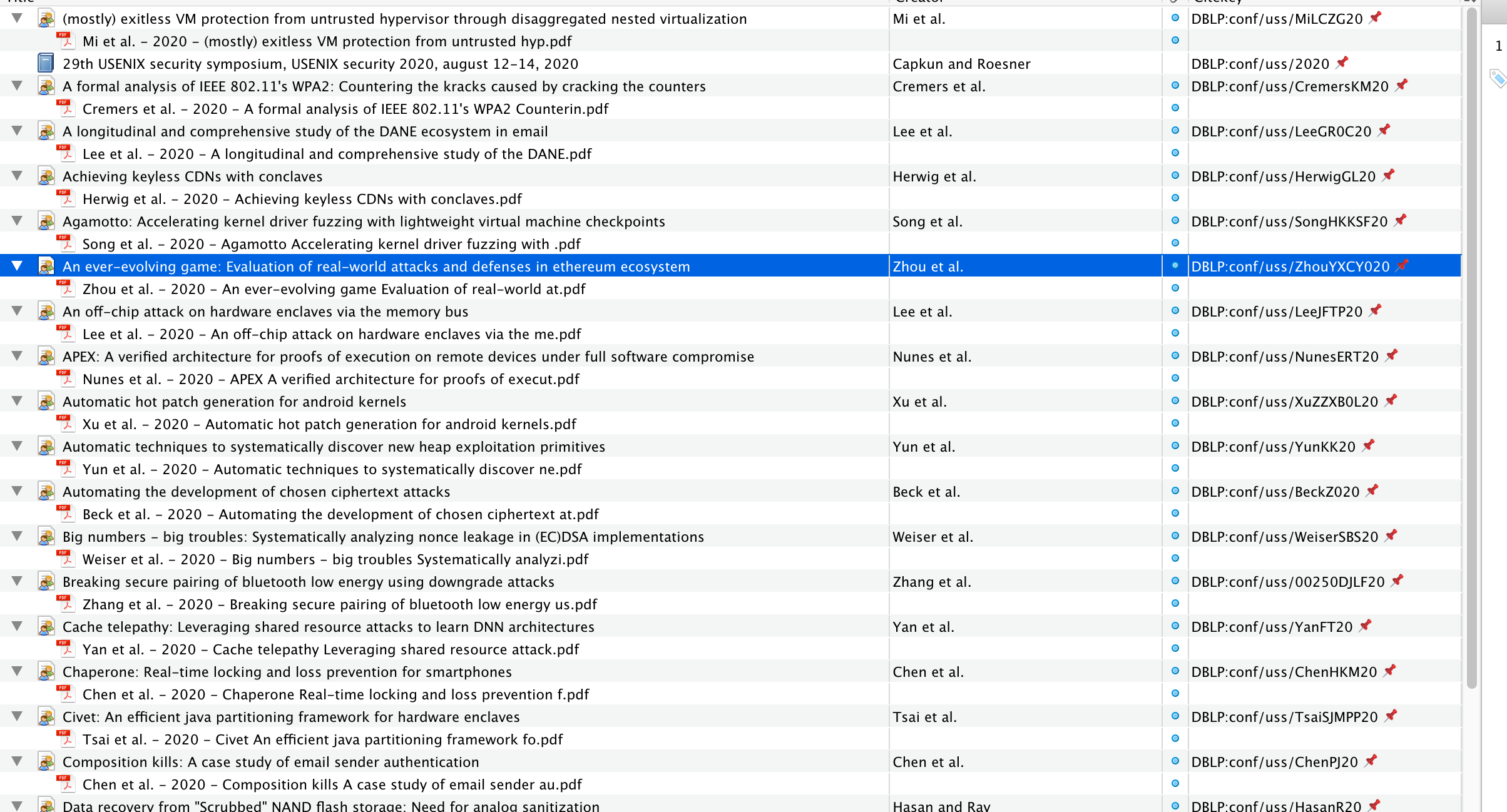
这个时候本地就会存储命名格式良好的论文。
简单的搜索,利用Alfred的in搜索命令即可。

高级搜索可以利用Zotero的搜索或者它自带的搜索:
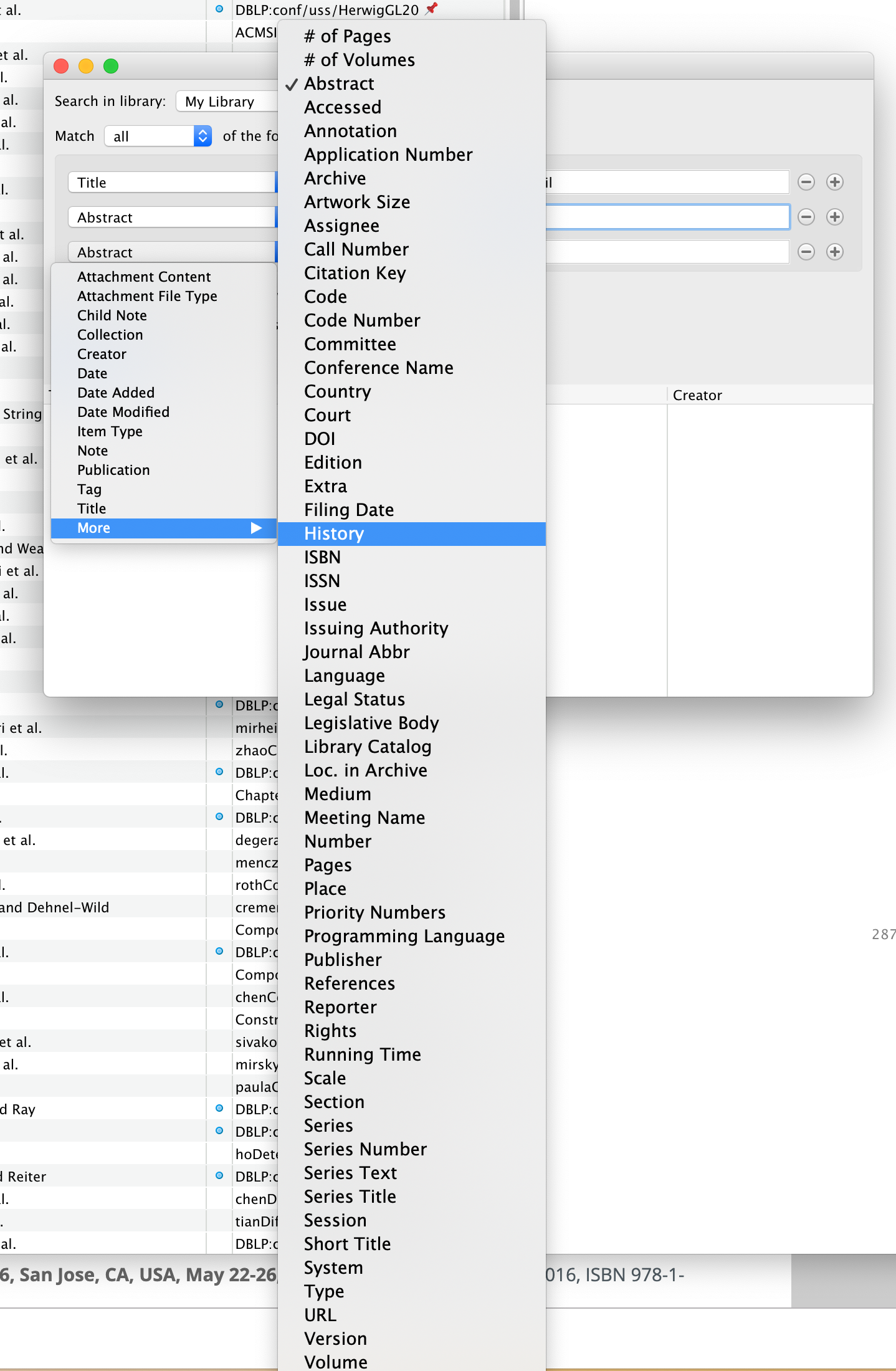
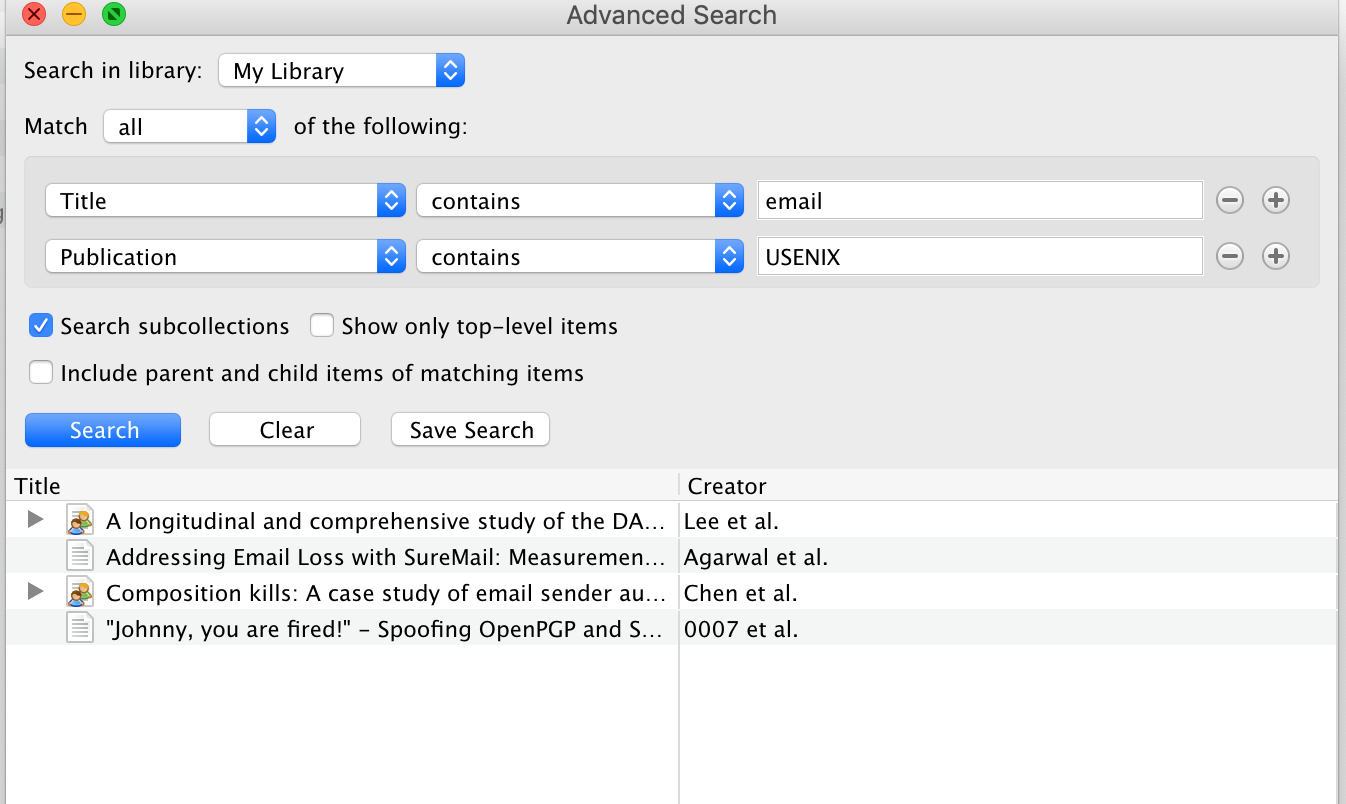
更精细化定制化的内容搜索,可以通过程序定制搜录pdf,然后基于数据集搜索即可。这一块,我们实验室的丰露同学已经做了尝试,而且效果很不错,为他点赞👍。
后续有精力的话,也准备做一些pdf和ppt解析,用于个人信息数据库的检索工作。
一些有趣的插件:
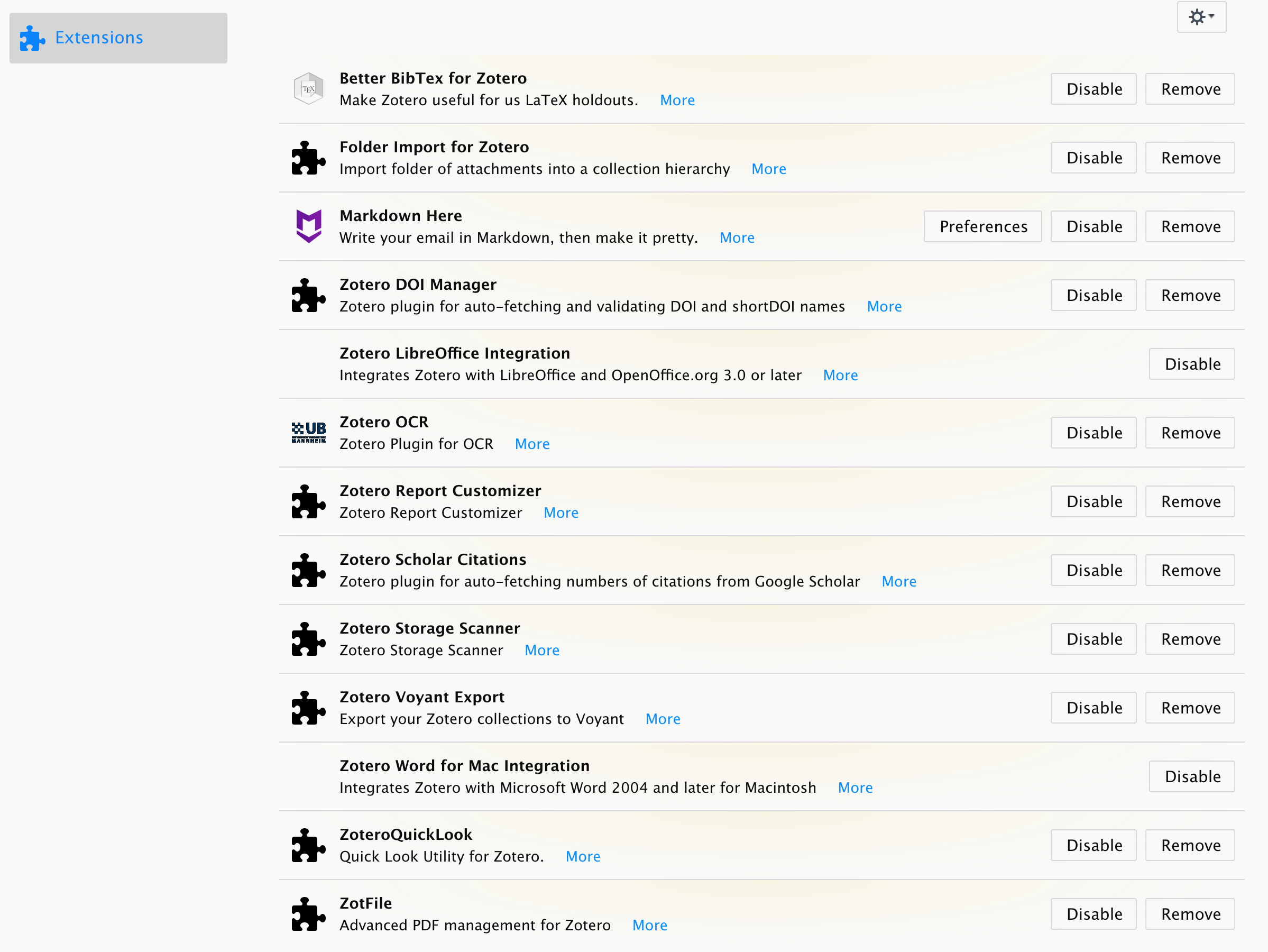
- Better BibTex 定制化引用格式,这一块好像主要用于中文的处理。
- Folder import for Zotero 支持文件夹导入pdf
- Markdown Here 支持markdown语法
- Zotero DOI Mangager 自动抓取doi。用于辅助Sci-Hub抓取pdf文件,非常好用。
- Zotero OCR 可以把一些扫描格式的pdf OCR转化一波,方便检索
- Report Cystomizer 导出论文相关信息
- Zotero Schlar Citations 用来更新文献的饮用次数
- Storage Scanner 扫描已损坏或者重复的论文
- ZotFile 用来批量重命名文件
另外,这个工具还可以配置坚果云同步。
其他推荐阅读
用于Zotero工具打造
后续可以继续做的事
- Zotero 虽然是开源的,但是代码量还是很大,定制化修改比较麻烦。后续可以学习下插件写法或者直接本地解析pdf,做一些后续的分析,比如pdf自动摘要生成、tag生成、论文引用关系、合作者等等关联信息分析,甚至还可以定向分析出每个会议收录会议的偏好、研究热点多年成长趋势图等。
- 可以提取论文的摘要,自动翻译推送整理一些会议的研究简报,可以快速地过一下每个会议论文的内容,感兴趣的再阅读对应的pdf。
- 基于pdf内容的分析,尤其是可以抓取一些工业界的技术pdf、博客、书籍,甚至可以加载一些非安全方面的内容(最近感觉研报很有意思!),这些内容都可以作为信息数据库的来源。
- 复杂的爬取,可以配合selnium类似的动态爬虫,加上crawlab的爬虫管理机制爬取。
- 目前这种方式没办法完成摘要的导入,后期可以考虑利用web of science来导入或者自己解析一波。不过,目前测试的web of science搜索起来结果不是特别新,不知道什么原因。有知道的同学可以反馈一波
最后,整理与搜集只是个人知识库完善的第一步,后续最重要的还是泛读+感兴趣的精读+思考与反思。加油,与你共勉。