浅谈浏览器工作原理
浏览器的结构
浏览器主要有以下几个组件:
- 用户界面/User Interface 包括浏览器主窗口、地址栏、前进/后退/停止/刷新等按钮、收藏夹等,其他显示的各个部分也都属于用户界面。
- 浏览器引擎/Browser Engine 处于用户界面和渲染引擎之间,负责在两者之间传递操作。
- 渲染引擎/Rendering Engine 负责显示请求的内容,对于HTML,就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络/Networking 用于网络调用,比如 HTTP 请求。
- 用户界面后端/UI Backend 用于绘制基本的窗口小部件,比如下拉框和窗口。
- JavaScript解释器/JavaScript Interpreter 解析和执行 JavaScript代码。
-
数据存储/Data Storage 这是数据持久层,浏览器需要将数据保存到本地硬盘,比如Cookie,浏览器还可以支持 localStorage, IndexedDB, WebSQL和FileSystem。
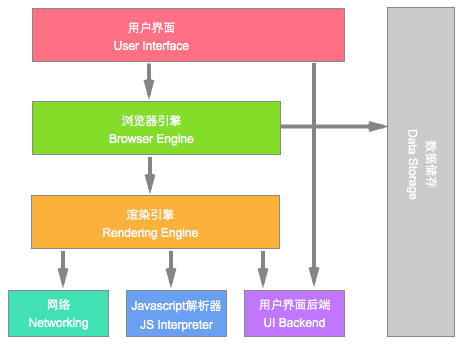 注:Chrome浏览器的每个标签页都分别对应一个渲染引擎实例,每个标签页都是一个进程(一定程度上,这就是为什么chrome浏览器比较占内存的原因)
注:Chrome浏览器的每个标签页都分别对应一个渲染引擎实例,每个标签页都是一个进程(一定程度上,这就是为什么chrome浏览器比较占内存的原因)
###渲染引擎
渲染引擎,我们一般也称为浏览器内核,可以说是浏览器最重要的一个模块。 Firefox使用基于Mozilla的Gecko,而Safari和Chrome使用的是Webkit。渲染引擎主要工作就是依据HTMl、XML、CSS等代码文档的描述,把页面显示出来。
####渲染引擎的基本流程
- 首先,渲染引擎会通过Networking组件获取请求的内容(HTML CSS JS代码之类的)
- 获取到内容后,渲染引擎会进行下列流程

- 对HTML文档进行解析,构造“DOM树”,并将各个标签转化为内容树的DOM节点
- 再解析来自内部和外部的CSS数据+HTML中带有视觉效果的指令,构建“渲染树(Render Tree)”,渲染树包含多个带有视觉属性(如颜色和尺寸)的矩形和矩形间的前后排列顺序。
- 然后,进入布局阶段,即为每一个节点分配一个应出现在屏幕上的确切坐标。
- 最后就是绘制渲染树,渲染引擎会遍历渲染树,通过用户界面后端,将节点绘制出来。 注:上面是大体流程,但实际情况,该流程并不是严格的顺序的。通俗讲就是,这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。但它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
一般,先HTML解析,再CSS解析,再JS解析
主流程范例
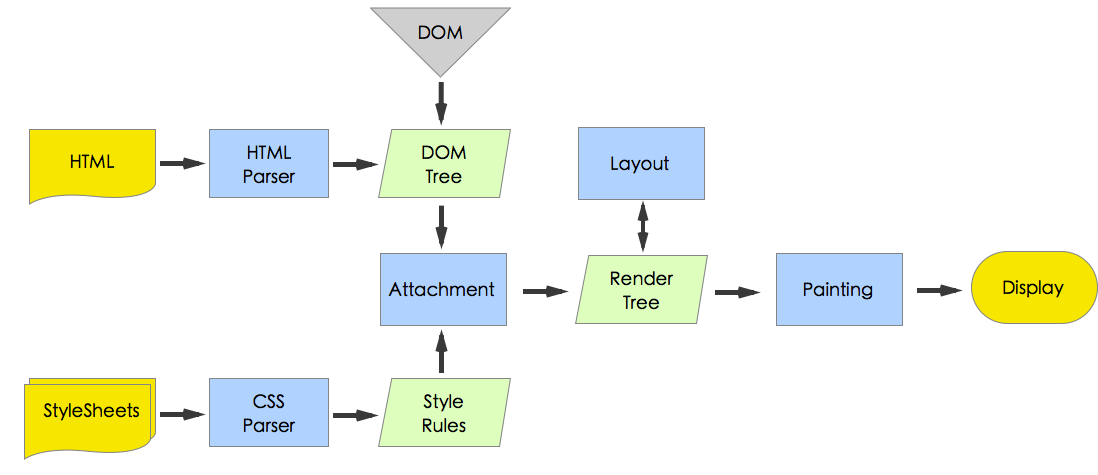
Webkit主要流程
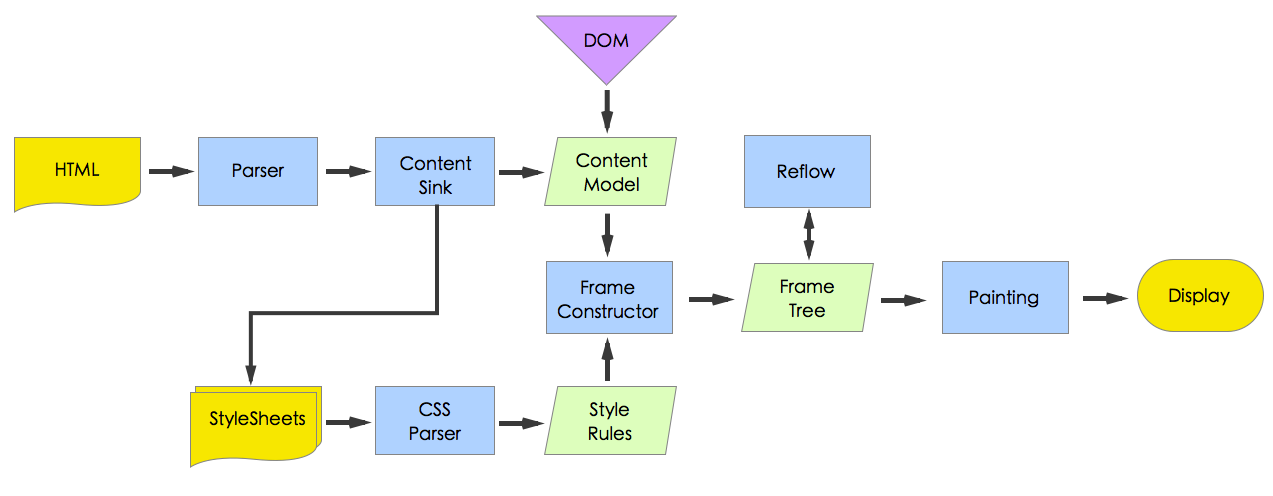
Gecko主要流程
其实,可以看出,两种内核虽然一些步骤叫法不一样,但是整体流程基本相同。
1.HTML解析
由于HTML有容错性,且有时源内容在解析过程中会发生改变(document.write),所以现今浏览器采用具有容错机制的解析器解析HTML代码。
大体流程如下图:

先依据网络模块获取原始数据,然后开始构建结构树,最终构建Dom树。在构建的同时,会依据一些脚本代码,对原始数据进行修改,然后依据修改内容相应修改最终的Dom树。
其中,我觉得最重要的一个是解析器(Parser)的主要过程:
词法分析和语法分析:
-
词法分析就是将输入分解为符号,符号是语言的词汇表——基本有效单元的集合。对于人类语言来说,它相当于我们字典中出现的所有单词。在解析器中,可以将输入分解为合法的符号,根据语言的语法规则分析文档结构,从而构建解析树,词法分析器知道怎么跳过空白和换行之类的无关字符。(就是个分词器- -)
-
语法分析指对语言应用语法规则。
对于下列代码:
<a href="javasc
ript:alert(1)">click</a> 首先html编码被还原出来 然后就成了换行 跟冒号
<a href="javasc
ript:alert(1)">click</a>
为什么换行后还能够执行 是因为浏览器中的解析器中词法分析器 起的作用会跳过空白跟换行之类的无效字符。
然后就构造成了一个完整的语句
<a href="javascript:alert(1)">click</a>
这就是为什么最开始的代码可以执行的原因
具体细节,可参考2中,HTML解析器部分
2.CSS解析
注:CSS解析错误的时候,浏览器会尝试忽略错误的代码。这点和HTML比较类似 具体样式如何解析就不详细介绍了,具体查阅CSS规范,下面讲CSS匹配:
为了提高样式匹配的效率,样式表解析完毕后,系统会根据选择器(包括 ID、类名称、标记名称等)将 CSS 规则添加到某个哈希表中,还有一种通用哈希表,适合不属于上述类别的规则。如果选择器是 ID,规则就会添加到 ID 表中;如果选择器是类,规则就会添加到类表中,依此类推。 这种处理可以大大简化规则匹配。无需查看每一条声明,只要从哈希表中提取元素的相关规则即可。这种优化方法可排除掉 95% 以上规则。
例如CSS:
p.error {color:red} /*插入类表*/
#message-div {height:50px}/*插入ID表*/
div {margin:5px} /*插入Tag表*/
table div {margin:5px} /*插入Tag表*/ 假设我们有HTML:
<div id="message-div">this is a message</div>
浏览器从ID表和Tag表中找出第2、3和4条,但是第4条会被抛弃,因为没有table祖先。由此也可见,浏览器在匹配样式规则的时候是由右往左的,所以在写样式的时候为了高效,要避免使用通配符。
另外我们都知道浏览器对于各个标签都有默认的样式,可以参考Default style sheet for HTML 4,加上我们编写的样式,浏览器的层叠顺序是如何的呢?
样式对象具有每个可视化属性一一对应的属性。如果某个属性未由任何匹配规则所定义,那么部分属性就可由父代元素样式对象继承。其他属性具有默认值,这就是为什么我们有时候可以把样式写在父节点上。如果定义不止一个,就会出现问题,需要通过层叠顺序来解决。根据 CSS2 规范,层叠的顺序为(优先级从低到高):
- 浏览器声明
- 用户普通声明
- 作者普通声明
- 作者重要声明
- 用户重要声明
Dirty位系统
为避免对所有细小更改都进行整体布局,浏览器采用了一种“dirty 位”系统。如果某个渲染器发生了更改,或者将自身及其子代标注为“dirty”,则需要进行布局。有两种标记:“dirty”和“children are dirty”。“children are dirty”表示尽管呈现器自身没有变化,但它至少有一个子代需要布局。
布局分为全局布局(同步)和增量布局(异步),当满足一下条件时会出发全局布局:
- 更改影响了所有渲染器的全局样式,例如更改字体大小
- 屏幕大小调整
绘制
绘制和布局类似,分为全局绘制和增量绘制。在增量绘制中,渲染器发生改变但没有影响到整个树,渲染器就将它在屏幕上对应的矩形区域设为无效,这导致系统将其视为一块“dirty 区域”,并生成“paint”事件。
3.JS解析
JS解析和HTML、CSS解析是不一样的,它不具有容错性。因此,JavaScript在语法错误的时候,整个代码都会被忽略。
参考
- http://feit.topming.com/how-modern-web-browsers-work/
- http://taligarsiel.com/Projects/howbrowserswork1.htm
- http://coolshell.cn/articles/9666.html